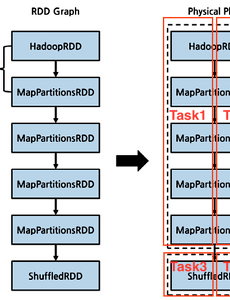
학습장59 spark 실행구조 Spark 대용량 데이터를 빠르게 처리하기 위한 인메모리 기반의 분산 데이터 처리 엔진 클러스터 환경에서 데이터를 병렬 처리하는 라이브러리 집합 spark 등장 배경은 MapReduce 단점 보완하기 위해 ?? 등장배경 "왜 갑자기 병렬 데이터 처리에 열광하게 되었을까" 와 같음 예전엔 CPU등 하드웨어 성능이 해마다 눈에 띄게 발전함 → 2005년쯤 부터는 물리적인 한계로 성능향상이 점점 둔화됨 (단일 프로세서의 성능이 급격하게 상승하다 2005년 이후 둔화) 이는 멀티 코어 프로세서가 탄생하는 계기가 됨, 하드웨어 엔지니어들은 병렬 CPU 코어를 추가하는 방향으로 선회 반면, 데이터를 저장하는 하드웨어의 가격은 저렴해짐 → 데이터 저장비용이 저렴해지며 저장할 데이터가 대용량화 됨 새로운 처리엔진과 프.. 2022. 10. 31. [spark] RDD란? RDD (Resilient Distributed Dataset) 스파크의 데이터 처리 모델 RDD는 대량의 데이터를 요소로 가지는 분산 컬렉션 클러스터 환경에서 분산처리를 전제로 설계 되었음 내부는 파티션이라는 단위로 나뉨 스파크에서는 '파티션'이 분산처리 단위 RDD가 데이터를 처리하는 방식 변환 (Transformation) ( ex. Filter, groupBy, map, ..) RDD를 가공하여 새로운 RDD를 얻는 처리 데이터가 이미 키값으로 파티셔닝 되어 있거나,, 하나의 노드 내에서 모두 처리할 수 있는 작업 .. 데이터 양이 적은 경우?, 변환 전의 RDD가 가지는 요소를 같은 RDD의 다른 요소와 함께 처리하는 변환 키와 밸류의 쌍을 요소로 갖는 RDD 같은 키를 갖는 요소를 한데 모아 .. 2022. 10. 24. M1 Mac anaconda 설치 anaconda 는 Python 개발환경을 쉽게 구축할 수 있도록 도와주는 일종의 패키지이다. anaconda를 설치하면 가상환경 등을 활용하여 개발환경 구축에 용이하고 데이터 처리나 분석 등에 관련한 라이브러리가 기본적으로 포함되어 있음. anaconda 설치 페이지를 가보니 M1 Mac은 설치파일이 또 별도로 존재함 https://www.anaconda.com/products/distribution#Downloads Anaconda | Anaconda Distribution Anaconda's open-source Distribution is the easiest way to perform Python/R data science and machine learning on a single machine.. 2022. 10. 20. 카카오 오류 블로그 운영 어떻할까? 카카오 오류 블로그 운영... #카카오 오류 사태 #티스토리 블로그 #앞으로 어떻해야할까.. 지난 10월 15일 SK C&C 센터에서 화재가 발생으로 인해 카카오의 서버 전원이 차단돼 카카오톡, 카카오 맵, 카카오페이, 카카오모빌리티, 카카오게임 등 얼어 서비스가 중단되었습니다. 이번 서비스 장애는 카카오가 메인 데이터센터로 이용하던 곳이 전력공급이 차단되면서 3만 2000개에 달하는 전체 서버가 다운되었습니다. 이와 달리 네이버는 3시간 안에 일부 서비스만 문제가 되고 다 복구되었습니다. 이전에 블로그를 운영하지 않았을 때는 단 몇시간 카카오톡이 안되어 불편했을 것 같지만 블로그를 운영하니 이번 사태는 아주 작지만 피해는 입은 것 같습니다. 카카오 티스토리를 운영하다 보니 다음에서 검색해도 해당 블로그.. 2022. 10. 17. 이전 1 ··· 4 5 6 7 8 9 10 ··· 15 다음 728x90